
Our use case seems to be the opposite of what PagerDuty currently supports. I know we can use the Dedup Key to merge alerts into an already open incident and help with grouping alerts.
However our use case is to not send a notification unless we have received X number of alerts in Y time. What we see is that a run will fail, but the next run in 15 mins is successful, so our on-call person is getting paged and then resolving the ticket because the next run was successful. Would be good to not page the On-call person unless the next run also fails. But haven’t seen how to handle this in PD. The Auto-Resolve doesn’t work in our case because they are individual alerts - from seperate runs of a pipeline - the dedup key is what links them.
Has anyone dealt with a use case like this? Have you been able to solve it?
Event Orchestration - Notify after X number of Alerts?
Best answer by mwalls
Hi
This feature is included in AIOps → Event Orchestration, specifically at the Service Orchestrations level. Once an event is routed to a service, the orchestration rules for that service can include thresholds that must be met for reporting that event. You don’t need to use a Global Orchestration to use this Service Orchestration feature, you can create these orchestrations for the service and send your events to the integration endpoint directly.
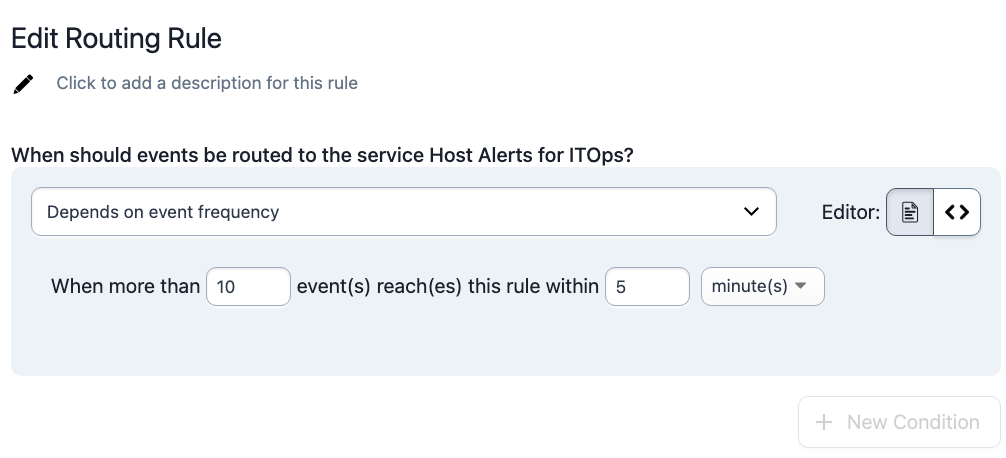
If you’d like a longer intro to Event Orchestration, reach out to your account team for a full demo. We also have some videos on our YouTube channel:
Pausing Incidents: https://www.youtube.com/watch?v=rkb_ut95Irw&ab_channel=PagerDutyInc.
EO tips and tricks: https://www.youtube.com/watch?v=MeQsfrhgD2k&t=21s&ab_channel=PagerDutyInc.
HTH,
--mandi
Login to PagerDuty Commons
No account yet? Create an account
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.